Concept Idea: Using client-side Javascript for distributed computing
Could we use client-side Javascript for distributed computing to solve the world's problems simply by having someone visit a webpage?
Earlier today I read this article about SETI (the Search for Extra-Terrestrial Intelligence) shutting down the Allen Telescope Array due to lack of funding.
SETI@home
That article reminded me of how, back when I ran Windows many years ago, I used SETI@home to donate my free computing cycles. Essentially this program is a screensaver that sits on your computer waiting for you to be idle. When idle, the screensaver pops on, and SETI@home goes to work.
SETI operated many satellites. These satellites listened for data, but the data came in faster than they could process it. So they had to find a solution. SETI@home arose out of this need.
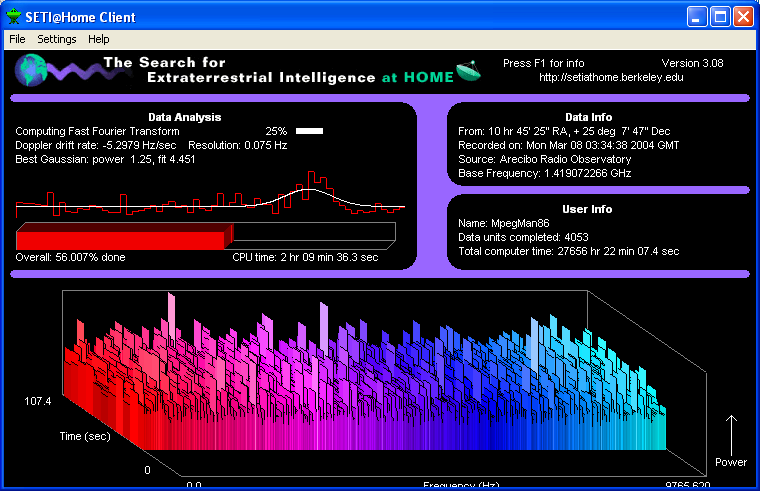
So the SETI program took the raw data it received from the satellite, got it into its servers and then it would break this raw data into small, manageable chunks. When a person had the SETI@home screensaver, it would automatically retrieve a chunk of data to analyze from the SETI servers and then would use the (otherwise) idle time to run its calculations on the data. When it was complete, it would send the finished analysis back to SETI who would re-assemble the pieces into meaningful results.
The concept is brilliant. By breaking the problem into many small chunks and running it as a screensaver, it was not inconveniencing any user as it ran only when a comptuer was not being used, and many could lend their idle processing power to the project. It cost them nothing and they were able to have many potential workers to sort out their data. For a program with a tight budget, this is certainly more appealing than investing in a large array of servers.
The reason I started this section “back when I ran Windows” was that when I first moved to using a Mac, I could not find a SETI@home screensaver client, so I stopped using it.
Barriers to Entry
After reading this article, I thought I would check it out again. There is now a client for OS X, but it is not pretty. One of the main issues with this approach is that the barrier to entry is high. Requiring people to install a screensaver in order to contribute is more than most users are ready and willing to do. Further, the program setup is very confusing. I downloaded the latest version from Berkeley’s SETI website. The program, is actually called BOINC and is a universal client for a bunch of different projects. Upon launch, I was greeted by this:
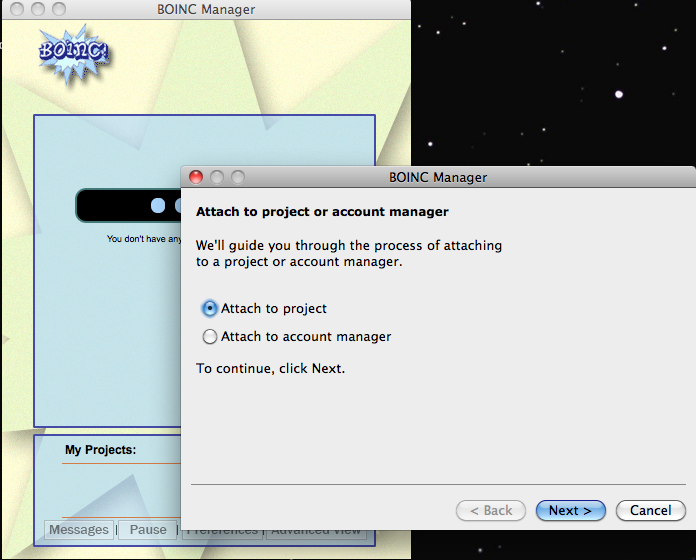
Not the prettiest interface, but that should be OK in theory. I picked SETI@home from the list of projects and got…this:
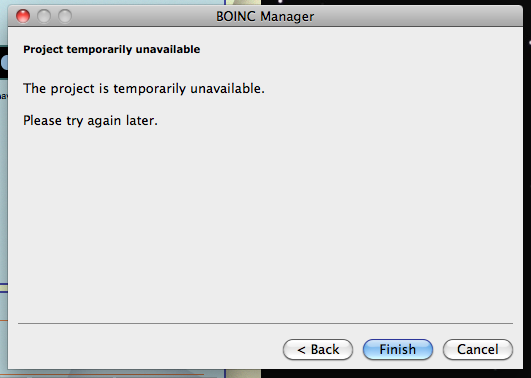
But now I’m determined to make it work. I want to donate my free CPU cycles to someone! So I tried MilkyWay@home and was in business. Now I have to create an account. It’s starting to become more of a pain than it’s worth:
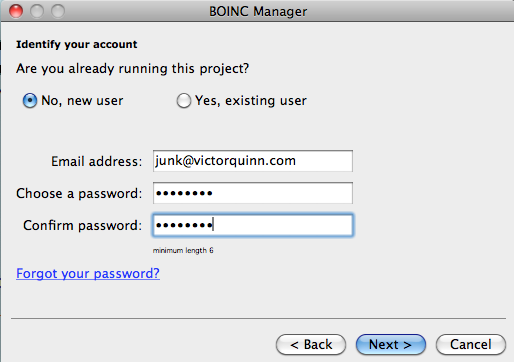
But I’m dedicated, I want to do this! So I do it and then I’m finally done with the setup…or so I thought. It opened a web browser and wanted more information:
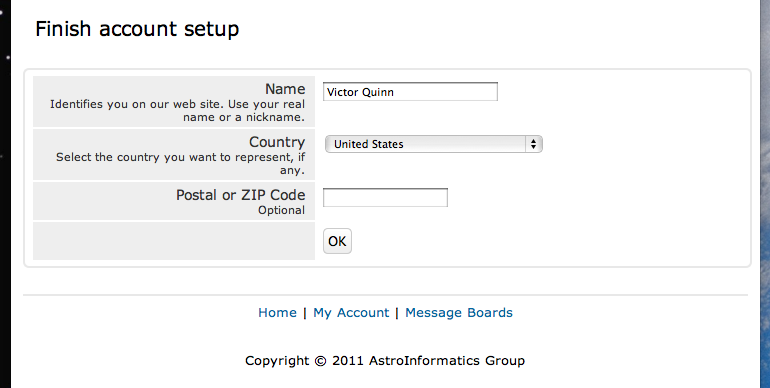
I just wanted to help donate some free computing, I don’t want to have to divulge all of my personal information in order to help out. At the same time that happened, this BOINC program looks like it’s doing something:
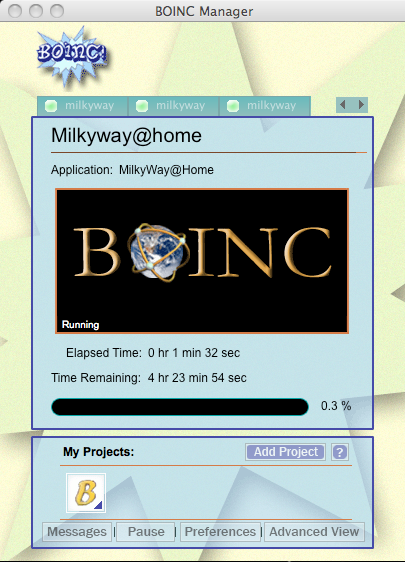
But why is it doing something? Isn’t this supposed to be a screensaver, using my idle computing time? Not right now when I’m actively using my computer! So I look in the Preferences.
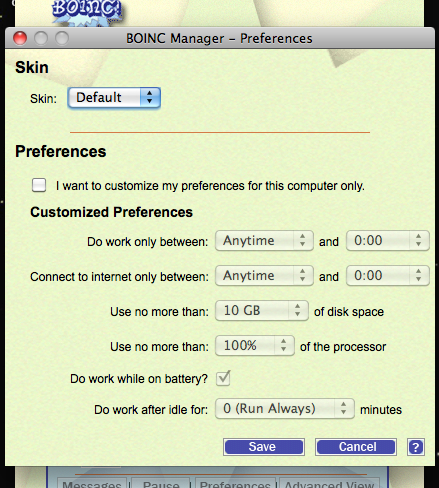
Notice “Do work after idle for:” is set to “0 (Run Always)”. That’s not what I want! I am fine with donating some free CPU, but I don’t want my performance degraded while I am trying to work. Now, I understand why they may have set this default, but in my opinion it is overly greedy. Of course they want as many CPU cycles as they can, so defaulting to always running on the computer of any installer will maximize that. But it does frustrate and anger me that I have to manually override the damned thing to make it not run constantly. And I thought this was supposed to be a screensaver? Why not just put all of the options into the screensaver settings? Why have a separate client like this.
Anyway, I’ll stop here because a review of the questionable UI of the BOINC software is not the goal of this article. This was probably written by some grad students with little or no budget. I get that. My point in here is to show that the barrier to entry is very high. I am a developer and I had trouble figuring out what was going on here. Good luck getting the masses to adopt such a thing.
Client-Side Javascript For Distributed Computing
As a web programmer, I am constantly writing software that is instantly available to all of our users. This is one aspect of web programming that I truly love. And this is great because it has almost NO barrier to entry. Anyone with a web browser can access something that I have made and use it to change their lives instantly. No downloading something, running it, etc.
Now why not re-write the SETI@home client in client-side javascript? Any user could point their browser at it and be in business, sharing the computing power of their machine with almost no friction. Even better, it could be deployed as a widget in iGoogle or any other homepage. Then I can just add the widget, leave iGoogle open on my computer and I’ll be making a contribution.
I don’t advocate for it, but it could conceivably be hidden from the user and deployed automatically on page load. Imagine if Facebook did this? While people were browsing on Facebook, they could conceivably deploy some code that would run on every user connected to their servers. If done intelligently enough, it could even be possible to use the CPU of clients to compute things for the other clients! Imagine if, instead of taxing the Facebook servers to create image thumbnails, Facebook received the full-size image upload, pushed it to a random user’s computer, then their machine, using the distributed computing libraries, created the derivative images and sent them back. This is a bit of a contrived example, this is not necessarily the type of thing distributing computing would best be used for, but it illustrates my point.
It would be very neat for someone to write a javascript library enabling this kind of thing which could then be extended and used by developers to implement other things. Much of this could be abstracted for the developer, leaving a simple and clean API which developers could leverage to send jobs to. Imagine if there were just a library called “distributed.js” or something that were in use by many different websites. So visiting any of these websites essentially spun up the client on your local machine. Then someone could send jobs which would get sent out to any client visiting a site which loaded the library.
While it seems on first glance that this could open a large security hole, one beautiful point is that it makes use of the existing security infrastructure in web browsers which isolates the javascript VM from the host machine. So it poses no danger to the host machine. Further, the data could be encrypted to help with security for the data. Though it could make their CPU spike and degrade their performance which is certainly poor practice, it is interesting to think of the possibilities.
While just a concept, I believe this has a lot of interesting potential…
If such an API library exists, let me know in the comments. I searched around for awhile and couldn’t find much.